
若想讓機器人分析/發掘資料中更深層情報進而能掌握趨勢、洞見未來並將知識傳承與運用, 需賦予它各式感測器使其自身有能力透過不斷嘗試錯誤(小孩子一開始也是很容易捏碎餅乾的, 直到逐漸掌握力道)與學習, 並將所接收到的視覺(圖案)與聽覺(音樂)訊息甚至是觸覺或嗅覺等刺激進一步跟人類智慧與抽象思維的結晶「文字符號」做鏈結, 以固化其內在獨有的特徵(feature)並逐漸獲得/累積「知識」.
上一回在「機器人(或AI)的知識擷取」中, 我們介紹了機器人取得知識的途徑, 其中也透過Wiki API幾乎可以回應人類所有的提問(例如科技、各國的通識、時事、娛樂新聞甚至是法律). 本篇文章想要更進一步讓機器人做夢, 即讓機器人在閱讀完一篇文章之後可以很快的找到「關鍵字詞」並自動向大腦(Google或Wiki)提相關取素材以產生圖案(甚至是動畫)與聲音或音樂等聯想. (當然, 若有業者能提供「向量媒體素材」的搜尋資料庫與API是最好的, 輸出效果肯定驚人!)
關鍵字詞(Key
Word)
假如給定一則短文如下圖, 相信每個人用眼睛掃瞄一遍大概就可以掌握住哪些字詞是「關鍵詞」, 哪些只是標點符號, 亦或哪些是副詞、介詞、助詞或連接詞等. 此外, 我們可能還對這些關鍵字詞出現的頻率甚至是大致的位置都還有些記憶, 因此我們可以很快地用筆圈出重點.

但是, 上述的工作若交由機器人來做就會變得蠻棘手的, 尤其是辨識中文的字詞甚至還有中英文夾雜的「晶晶體」, 困難度非常高! 人類對於關鍵詞的敏感度, 事實上有絕大多數是從常年閱讀的文章中逐漸積累的體驗所轉化而來, 因此很難由單篇文章定奪. 例如: 「狹義相對論」中的「狹」在整則短文中雖然只出現兩次, 但我們依然認為整個「狹(2)義相對論」詞組為一關鍵詞, 而不是機率較高的「義(4)相對論」.
中文的字詞可以是由一個以上的字元所組成, 其意義和所構成的個別字元也可能無關(例如「相對論」), 字詞與字詞之間也沒有固定的邊界. 此外, 在一串字組中切割點選擇的不同其意義上的解讀也會大不同, 例如: 究竟該切成「台灣/國立大學」兩個字詞、「台灣/國立/大學」三個字詞或是「台灣國/立/大學」取二捨一? 撇開標點符號之後, 若還要能夠精準分割與篩選出關鍵, 這得依賴人類長期積累下來的「知識」與其對「文法結構」的認知.
中文關鍵詞分析
關於中文的關鍵詞分析, 前面我們稍微提及它的困難度, 因此有許多專業的學術研究與文獻討論. 一般正規的做法有所謂的「斷詞技術」, 即讓電腦把詞彙以「意義」為單位切割出來, 再將字詞重新組合. 實作上我們可以捨棄字詞中相對較沒有意義的部份, 但除了去蕪存菁還要能夠保證關鍵字與主題之間的關聯性以提昇分析的準確度. 但是, 何謂「意義」呢? (一堆預定規則嗎?) 因此, 可以預見它將不適合運用在辨識「流行語」或普遍存在於社群網站的「晶晶體」.
更進階的還有所謂的「自然語言處理」技術, 其運用了機率與統計的方法結合「機器學習(Machine Learning)」及「資料挖掘(Data Mining)」, 搭配「文法規則」與「語料庫」來解決前面所描述之難題. 但這已超出筆者的領域與本文想討論的範疇, 有興趣的讀者可以自行參閱相關的論文.
筆者希望能透過簡單的Python程式(無需「文法規則」或依賴任何「語料庫」), 亦能夠(盡量)精準而有效率地對文章進行關鍵詞(主題)搜索, 並自動鏈結關於該關鍵詞的多種不同素材(圖片與音樂等)以達成「關聯性聯想」的效果.
字頻(Word
Frequency)
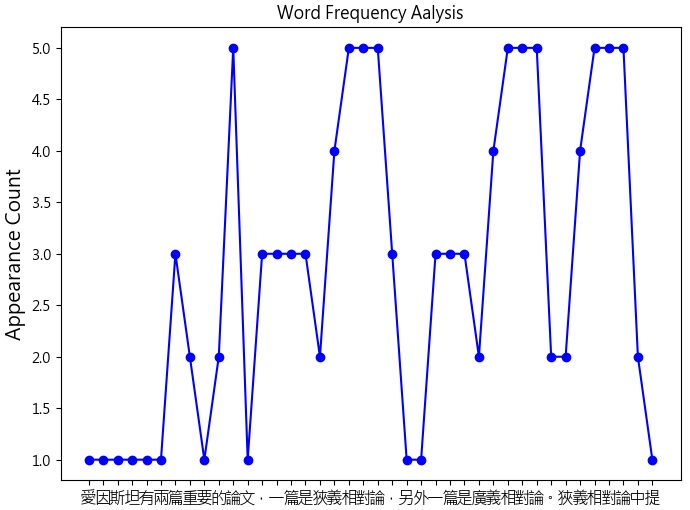
若以前面關於「愛因斯坦」的短文為所輸入的文章內容, 我們可以將「字頻(word frequency)」的統計結果輸出如下. 我們可以把「字頻」想像為: 個別中文單字在整篇文章中所出現的機率(次數).

下面程式碼透過Python的「字典(hash)」功能, 能對所輸入的整篇文章建立以「中文單字元」為索引的計數器.
# build word frequency by
key
def word_freq_by_key(text):
wFreqKey={}
for w in text:
if w==' ':
wFreqKey[w]=0
continue
if wFreqKey.get(w)!=None:
wFreqKey[w]+=1
else:
wFreqKey[w]=1
return wFreqKey
|
之前我們大致提到中文字詞切割的困難度, 可以想像這些個別的單一字元、詞或詞組彼此之間並非為正交向量(也不存在). 一般正規的做法通常以機率為基礎的算法, 例如「條件隨機域(Conditional Random Field, 簡稱CRF)」, 透過「分詞資料庫」來將原本的文字序列切割成數個字詞(以詞為單位的向量)以組合成新的「結構化文字序列」. 有興趣的讀者可以搜尋「CRF
word segmentation」的相關論文, 但這不在本文章的討論範圍.
若我們把前面以「字典」統計得到的各單一「字頻(word
frequency)」套回原本文章中的相對位置, 仍然可以得到如下圖的「空間-詞頻輪廓(space-term frequency profile)」. 例如: 「相對論」在整則短文中共出現了5次, 而「義」字共出現了4次.
若我們以上一回「機器人(或AI)的知識擷取」中所提及, 以OCR掃描「格林童話故事-青蛙王子」為文章的輸入源. 下面這段程式碼則以Python的「串列(list)」功能, 將之前所得到的單一字頻拓展回原始文章的位置以得到文章的「空間-詞頻輪廓」.
# build term frequency
profile
def word_freq_by_pos(text,wFreqKey):
size=len(text)
wFreqPos=[]
for i in range(0,size):
w=text[i]
wFreqPos.append(wFreqKey[w])
return wFreqPos
|

由於中文的字詞不像「段落」或「句子」可以透過明顯的標點符號來劃分界線, 所以在中文字詞分割(segmentation)的方法上會比英文字詞分割要複雜的多. 但從上圖的「詞頻輪廓」中我們可以發現一些有趣的觀察與現象, 當然這也是人類目前保有的優勢.
例如, 「關鍵字」的字頻較高者其左右鄰居字頻也相對較高. 在一串連續的字頻之間常常可以發現數個「釘狀(spike)」的波形起伏(該字出現的機率通常大於總體字頻的平均+3σ), 若忽略標點符號則該處通常是副詞、助詞、介詞或連接詞等的機率極高. 此外還可以觀察到, 若字頻的波形特徵(feature)在一短區間內呈高頻振盪時通常是在描述一個情緒、語氣、狀態或動作, 如下圖(為刪除標點符號後的空間-詞頻輪廓).

詞組分割(Phrase
Segmentation)
談到這兒, 好像有點偏向學術研究了! 但筆者比較感興趣的是: 如何以比較簡單且快速的方法找到關鍵字詞, 以產生後續更深層的運用, 例如機器人「視覺或聽覺的聯想」. 因此下面我們用的方式會比較另類, 但無須做事前的「樣本訓練」或依賴「分詞資料庫」, 同時可以達到不錯的效果. (在古代, 筆者應該是屬於「實驗物理」學派的)
前面我們有討論到中文字詞在描述不同的動作、語氣、情緒狀態或詞性本質時, 其詞頻在空間的拓展會有一些獨特的特徵(feature). 一個出現頻率高的字, 其左右兩邊鄰近的字通常呈單調(monotonic)的遞增或遞減(數學上稱「凸邊形」或「可微分」), 否則該字為副詞、介詞、助詞或連接詞的機率極高(spkie
noise).
為加快處理速度, 首先我們針對輸入的文章內容(content)作一些預處理, 例如將所有標點符號或運算元等置換成空白並令其字頻為零, 並根據「經驗法則」(筆者根據十幾篇童話故事書文章的實驗結果)將可能造成釘狀雜訊波形(spike noise)的字詞也都預先置換成空白並令其字頻為零. 請注意, 這裡所謂的「經驗法則」可能針對不同的文章性質需要作調整, 例如為「專利文章」建立關鍵字檢索或處裡充斥著「晶晶體」的部落格文章等.
而文章內容(content)的來源可以是透過ORC、資料庫、REST API查詢或是爬蟲程式得到, 請參考「機器人(或AI)的知識擷取」. 當然也可以用鍵盤輸入(如下例)或是剪貼(copy and paste), 若讀者很勤奮的話!
# special rule for chinese story
content=’’’愛因斯坦有兩篇重要的論文,一篇是狹義相對論,另外一篇是廣義相對論。’’’
text=content
text=re.sub(r'[,,:;、‧。「」『』!?!?….\t\n\s]+',' ',text) #
waive symbols
|
下面程式碼則透過Request與BeautifulSoup套件從網路上爬一篇「青蛙王子」的童話故事為範例, 並透過re (regular expression)將所有標點符號與我們預先定義的規則都丟掉來當我們機器人的知識來源.
import requests
import re
from bs4
import BeautifulSoup
# 讀故事
url='https://tw.ixdzs.com/read/111/111683/26727259.html' # 青蛙王子
html=requests.get(url)
html.encoding='utf-8'
sp=BeautifulSoup(html.text,'html.parser')
# grab string only
content=sp.find('div',class_="content").get_text(strip=True)
# special rule for chinese
stroy
text=content
text=re.sub(r'[,,:;、‧。「」『』!?!?….\t\n\s]+',' ',text) # waive symbols
text=re.sub(r'[+\-*/><=()()\[\]\'\"]+',' ',text) # waive symbol
text=re.sub(r'[把的了呀什麼呢也]+',' ',text) # waive spike
|
若將轉換成空間-詞頻(space-term-frequency)的輪廓想成對時間變化的波形輸入, 我們便可以基於k-最鄰近(k-NN)分群算法的概念設計一個「最小梯度濾波器(Minimal Gradient Filter)」來過濾上述可能是雜訊的釘狀(spike)波形. 它像是一個低通濾波器(low pass filter), 把文章中可能是副詞、介詞、連接詞或助詞(也有可能是代詞)等語彙過濾掉, 只保留狀態語彙(註: 筆者沒花太多時間或心思在這上面, 讀者可以自行改良它).
下面程式碼將持續收錄各個單字(w)到一詞類別(cat), 直到前後字頻的機率梯度差超過設定門檻(delta). 並將造成釘狀詞頻(spike frequency)的相對位置(通常為標點符號、副詞、介詞、助詞與連接詞等)收錄到另一個串列裡(wfFilter), 以對原始文章進行過濾. 其中, 字頻低於兩次或空白字元的就直接剔除. 原則上, 處理中文文章可以先剔除所有英文字元, 但我們仍然保留大寫英文字母. 可以透過函式ord(‘A’)與ord(‘Z’), 分別取得英文字元A與Z的ASCII code.
#
minimal gradient filter
def gradient_filter(text,delta):
size=len(text)
wfKey=word_freq_by_key(text)
wfPos=word_freq_by_pos(text,wfKey)
wfFilter=[0]*size
w=text[0]
cat=[w]
wlist=[] # list of phrase
for i in range(1,size):
w=text[i]
fp=wfPos[i-1] # previous word frequency
fc=wfPos[i] # current word frequency
if (abs(fc-fp)<delta and fc>2 and w!=' ') or \
(ord(w)>=ord('A') and ord(w)<=ord('Z')): # continue
collecting
cat.append(w)
wfFilter[i]=delta
else: # pop up a phrase
if len(cat)>1:
wlist.append(''.join(cat))
if w!=' ' and fc>2:
cat=[w]
# start collection
else:
cat.clear()
return wlist,wfFilter
|
Python有許多原生強大的數學與統計分析套件, 比如計算群體的平均值(mean)或變異數(standard deviation)這檔事只要將原本的串列(list)資料型別轉換成NumPy的陣列(array)即可. 其中梯度臨界值(k)的選擇, 是我們根據十幾篇童話故事內容的實驗結果得到(效果還不錯), 大約是總體字頻平均(μ)值再加上0.7倍的變異數(σ)值, 或是直接以k=1.5σ~2σ的設定值.
# analyze word and term
frequency
wfKey=word_freq_by_key(text)
wfPos=word_freq_by_pos(text,wfKey)
# calculate mean and
standard deviation
# k-MM: mean+0.7*std
import numpy
as np
d=np.array(wfPos)
k=int(d.mean()+0.7*d.std())
# phrase segmentation
wlist,wfFilter=gradient_filter(text,k)
|
以事先濾除所有標點符號的摘要短文「…哭著哭著 小公主突然聽見有人大聲說 唉呀 公主 您這是怎麼啦…」為例, 濾波器輸出的結果以串列(wlist)傳回並將詞組分割成: 「哭著哭著」、「小公主」、「突然聽見有人大聲說」、「唉呀」、「公主」、「您這是」、「怎麼啦」.

我們可以透過Matplotlib套件把之前所題的概念視覺化, 以產生更多可能的洞見或新的想法(演算法).
from matplotlib
import pyplot as plt
# space-term frequency and
filter
s,e=0,40 #
text range for analysis
xtics=list(range(0,len(text)))
plt.title('Word Frequency (Minimal
Gradient)')
plt.ylabel('Appearance
Count',fontsize=12)
plt.xticks(xtics[s:e],text[s:e],fontsize=10)
plt.plot(xtics[s:e],wfPos[s:e], 'b--o',
label='wfPos')
plt.plot(xtics[s:e],wfFilter[s:e],'r-',label='Filter')
plt.legend()
plt.show()
print(wlist[0:10])
|
當然, 濾波器輸出的結果並不是百分之百完美. 以事先去除所有標點符號的摘要短文「…水潭很深 在天熱的時候 小公主常常來到這片森林 坐在清涼的水潭邊上 她坐在那裡..」為例, 濾波器輸出的結果如下(將詞組分割成): 「水潭很深」、「時候」、「小公主」、「來到這」、「片森林」、「水潭邊」、「她坐」、「那裡」.

我們將濾波器輸出的結果重組之後, 再透過一個寬度(關鍵詞長度)可調的「滑動窗(sliding window)」, 即可把我們感興趣的「關鍵詞」全部篩選出來並存放在串列(keyList). 其中, 我們用product運算(字詞內所有字頻的乘積)將包含空白(或段落其字頻為零)的詞剔除, 而另外賦予大寫英文字較高的權重(v=2). 按照經驗, 中文文章內嵌英文大寫的場合通常是針對某特殊名詞的解釋.
我們針對不同「滑動窗大小(即字詞長度)」定義了欲輸出「關鍵詞數量」(依詞頻率排序)的表格(sw2oNum), 其中最大長度為9個字元而最小為2個字元. 例如, 當所搜尋到關鍵詞長度為7~9個字元時只輸出一個詞(依詞頻率排序), 而當所搜尋到關鍵詞長度為2~3個字元時只輸出三個詞(依詞頻率排序).
# grab key word with
adjusted sliding window
def product(wlist):
s=1
for e in wlist:
s*=e
return s
def get_key_word(text,sw=2,outNum=3):
wFreqKey=word_freq_by_key(text)
wFreqPos=word_freq_by_pos(text,wFreqKey)
size=len(text)
th=3
wCnt={} # term frequency
for i in range(0,size-sw):
w=text[i:i+sw]
if w.find(' ')!=-1 or product(wFreqPos[i:i+sw])==0: # waive
continue
if ord(w[0])>=ord('A') and ord(w[0])<=ord('Z'):
v=2
# high weight A-Z
else:
v=1
if wCnt.get(w)!=None:
wCnt[w]+=v
else:
wCnt[w]=v
iCnt={}
for w in wCnt:
n=wCnt[w]
if n<2:
continue #
waive low frequency
if iCnt.get(n)!=None:
iCnt[n].append(w)
else:
iCnt[n]=[w]
nl=[] # rank by requency
for n in iCnt:
nl.append(n)
nl.sort(reverse=True)
wList=[]
cnt=0
for i in range(0,outNum):
if i>=len(nl):
break
n=nl[i]
if n<th:
continue
for w in iCnt[n]:
if cnt>=outNum:
break
cnt+=1
print("%-10s %d" %
(w,wCnt[w]))
wList.append(w)
text=text.replace(w,' ') # remove key word
return wList,text
#################################
# reassemble terms
test=' '.join(wlist)
# grab key words with
sliding window
sw2oNum={9:1,8:1,7:1,6:1,5:2,4:2,3:3,2:3}
keyList=[]
for sw in range(9,1,-1):
wnlist,test=get_key_word(test,sw,sw2oNum[sw])
keyList+=wnlist
|
找到關鍵詞之後, 便交由後續的網路爬蟲對其大腦(Google或Wiki)查詢並據此題材以收集/產生「視覺」與「聽覺」等「聯想素材」. 例如, 若產生的關鍵字詞為「金球撈出來」、「到水潭裡去」、「突然聽見」、「忠心耿耿」、「小公主」、「水潭裡」、「青蛙」、「金球」與「國王」. 接下來我們則要以這些關鍵字詞為輸入, 進一步在上網爬些「可能符合」的聲音與圖片等素材.
下面程式碼可依使用者設定的圖案風格(例如臉部特寫、相片、插圖、線條藝術或動畫等不同風格), 透過Google API動態搜尋10幅「圖案素材」並隨機選取其中一幅成為輸出(成為機器人閱讀之後的夢境).
from urllib.request
import urlopen
import random
# 各種風格的圖片素材
apiImage={
'any':
'https://www.google.com.tw/search?tbm=isch&q=',
'face':'https://www.google.com.tw/search?tbm=isch&tbs=itp:face&q=',
'clipart':'https://www.google.com.tw/search?tbm=isch&tbs=itp:clipart&q=',
'photo':'https://www.google.com.tw/search?tbm=isch&tbs=itp:photo&q=',
'lineart':
'https://www.google.com.tw/search?tbm=isch&tbs=itp:lineart&q=',
'animated':'https://www.google.com.tw/search?tbm=isch&tbs=itp:animated&q='
}
# knowledge association -
vision
def vision_association(keyList,style='any'):
if style=='random' or apiImage.get(style)==None:
slist=list(apiImage.keys())
n=len(slist)
i=random.randrange(0,n)
style=slist[i]
print('Start dreaming with {} style'.format(style))
imgMaterial={} # selected image source
for item in keyList:
url=apiImage[style]+item
html=requests.get(url)
sp=BeautifulSoup(html.text,'html.parser')
# random pick one image from the top
10 Google's pictures
aList=sp.select('img',limit=10)
i=random.randrange(0,10) # random select one
image for the result
src=aList[i].get('src') # id=0, always
select the top most from Google
print(item+" : "+src)
imgMaterial[item]=src
img=plt.imread(urlopen(src),0)
plt.imshow(img,cmap='gray')
plt.show()
return imgMaterial
#################################
# robot dreaming
imgMaterial=vision_association(keyList,style='any')
|
當然, 「聯想素材」最好能有支援「向量圖」並且能符合各式場景所需之「聲音素材」等搜尋資料庫. 倘若跟筆者一樣, 無論是「知識來源(文章)」或是甚麼「素材資料庫」都沒有的話, 我們還是可以透過爬蟲程式從Google或Wiki那兒收集到「相關知識(文章)」以及「可能符合的題材」. 雖然效果可能會大打折扣, 但我們還是可以展示未來「機器人聯想」的無限可能.
本例的機器人作夢/視覺聯想結果如下(依關鍵字出現頻率排序):





若搭配「聲音素材」, 可以再將原本純文字的文章插入圖形與背景音樂(也可利用BeautifulSoup重新輸出HTML), 使其變為圖文並茂的多媒體故事書呢! 由於筆者手邊沒有合適的「音樂素材」資料庫可供搜尋利用, 因此本例只透過隨機抓取HTML教學網站所提供的媒體資料做展示.
# knowledge association -
hearing
def hearing_association():
url='http://www.pcnet.idv.tw/pcnet/html/images/'
music=url+str(random.randrange(1,7))+'.mid' # random select one music
material
return music
def build_html(text,imgMaterial,outfile):
music=hearing_association()
html='<html><head>'
html+='<meta charset="UTF-8">'
html+='<bgsound src={} loop="infinite">'.format(music)
html+='<title>Robot Dreaming</title>'
html+='</head>'
html+='<body>'
ikeys={} # grab key word index
for key in imgMaterial:
si=text.index(key)
ikeys[si]=key
ilist=list(ikeys.keys())
ilist.sort()
bi=0
for si in ilist:
key=ikeys[si]
ei=si+len(key)
html+=text[bi:ei]
html+='<img src="{}"></img>'.format(imgMaterial[key])
bi=ei
html+=text[bi:-1]
html+='</body></html>'
f=open(outfile,'w',encoding='UTF-8')
f.write(html)
f.close()
print("HTML was saved into '%s' ..." % outfile)
#################################
# robot dreaming
imgMaterial=vision_association(keyList,style='any')
build_html(content,imgMaterial,'robot_dreaming.html')
|

動態產生的HTML每次都有隨機的插圖與背景音樂, 雖然實用性不足, 但娛樂性實足呢!


# special rule for chinese
patent & 晶晶體
text=re.sub(r'[0
text=re.sub(r'["我們透過在]+',' ',text) # blog search
text=re.sub(r'[本發明包含實施例對應()]+',' ',text) # patent search
|
筆者再嘗試把以前寫的專利「動態拼接螢幕之播放系統及其方法」拿出來分析(使其自動產生專利檢索), 效果雖然差強人意, 但讀專利時有插圖可看還有音樂可聽也算享受! (嗯… 圖片若有牛頭不對馬嘴的話, 絕對是Google的問題!)

順便爬自己寫的部落格文章「機器人(或AI)的知識擷取」, 結果蠻無理頭的! 因為英文小寫全部先被剃除了(為了處理晶晶體), 因此失去了一些英文關鍵字. 若讀者想要做的更完美, 還是多花一些時間研讀一下正規的論文吧(例如「統計自然語言處理學」), 並引用一些專業的「字詞資料庫」吧!

這不是AI啊!?
若任何加速矩陣運算的晶片或架構都爭著冠上「AI晶片」封號的話, 那毫無疑問地「Bitcoin挖礦機」絕對是「AI晶片」的先鋒者! 書名標「Neural-Fuzzy」或「Big-Data」肯定不好賣了, 把它貼上「機器學習與AI」重新包裝之後賣相更佳! (既使是傳統的Excel、程式語言或電腦相關書籍也標AI就對了, 包括本文章標題)
很可惜, 目前Amazon AVS (Amazon
Voice Service)只支援英文語音, 否則我們還能請Alexa幫我們讀一下中文故事書呢! (魔鏡公公應該找Amazon談合作的, 營業額會增加兩倍以上, Win-Win!)