
機器人視覺
小baby總是對新鮮事物充滿了好奇心, 看到新鮮的東西就會用小手去戳一戳摸一摸. 透過「視覺」輸入而獲得的環境線索隨之增加, 於是他們能在心中規劃著未來探索的藍圖並且不斷的加深自己對這個世界的了解.
因此, 若假設自己的AI是個剛會爬行而且是正在探索世界與學習的小baby, 「視覺能力」會是一個很不錯的切入點. 而隨著時間的推移, 小baby (AI)可能會想要看到更多不同的視野以探索更多的未知領域.
人臉識別
-- 使用 Python+OpenCV
關於OpenCV如何讀取圖形與顯示的詳細說明, 請參考官網的文件資料, 安裝程序請參考上一回「開啟AI的修羅之路」的設定, 建議先安裝在虛擬器上試玩. 下面的程式碼即透過CV2套件讀取影像檔案, 以其內建的分類器(haarcascade_frontalface_alt2.xml)從中辨識出人臉並且用矩形以辨識成功的順序將其標示出來.
import cv2
cv2.namedWindow("FaceDetectWin",cv2.WINDOW_AUTOSIZE)
img=cv2.imread("Twice.jpg")
classifierXml="{安裝路徑}\
\\Anaconda3\\pkgs\\opencv3-
faceCascade=cv2.CascadeClassifier(classifierXml)
faces=faceCascade.detectMultiScale(
img,
scaleFactor=1.1,
minNeighbors=4,
minSize=(10,10),
flags=cv2.CASCADE_SCALE_IMAGE)
i=1
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(128,255,0),2)
cv2.putText(img,str(i),(x+20,y+20),cv2.FONT_HERSHEY_SIMPLEX,1,(150,200,50),2)
i+=1
cv2.imshow("FaceDetectWin",img)
cv2.waitKey(0)
cv2.destroyAllWindows()
|
事實上, 我們並沒有寫幾行程式碼, 幾乎都是套現成的函式庫呼叫而已. 首先, 我們從網路上抓一些公開、免授權且可利用再修改的圖檔(圖為偶像團體Twice)來測試一下效果.

辨識結果如下圖, 成功抓到9張臉孔, 而辨識順序以矩形框與數字直接貼在原圖上

再加上一些程式碼(藍色字體), 透過PIL套件的Image方法將辨識出來的人臉切割並scale成200x200像素以JPEG檔案儲存.
import cv2
from PIL import Image
cv2.namedWindow("FaceDetectWin",cv2.WINDOW_AUTOSIZE)
jpg=cv2.imread("Twice.jpg")
img=cv2.imread(jpg)
classifierXml="{安裝路徑}\
\\Anaconda3\\pkgs\\opencv3-
faceCascade=cv2.CascadeClassifier(classifierXml)
faces=faceCascade.detectMultiScale(
img,
scaleFactor=1.1,
minNeighbors=4,
minSize=(10,10),
flags=cv2.CASCADE_SCALE_IMAGE)
cv2.putText(img,"Find
"+str(len(faces))+" faces",\
(10,img.shape[0]-45),cv2.FONT_HERSHEY_SIMPLEX,1,(255,160,180),2)
i=1
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(128,255,0),2)
cv2.putText(img,str(i),(x+20,y+20),cv2.FONT_HERSHEY_SIMPLEX,1,(150,200,50),2)
cutFile=”face”+str(i)+".jpg"
cutImage=Image.open(jpg).crop((x,y,x+w,y+h)).resize((200,200),Image.ANTIALIAS)
cutImage.save(cutFile)
i+=1
cv2.imshow("FaceDetectWin",img)
cv2.waitKey(0)
cv2.destroyAllWindows()
|
執行結果可以透過檔案總管, 瀏覽各別儲存成200x200像素的JPEG檔案.

處理一般正面角度的多人合照(圖為偶像團體FT Island, 同樣是可利用再修改的授權方式)表現都蠻不錯, 基本上都能成功辨識.


但處理有不同景深的團體合照表現就差強人意了! 如下圖就漏掉一張應該可以明顯辨識的臉(最右側正面數來第二位), 是因為戴眼鏡的關係嗎?


若團體照中包含了許多不同角度, 處理結果就不太好, 下圖一群畢業學生只能抓到9張臉. 不過仍能成功辨識幾張3/4側臉, 好玩吧?!



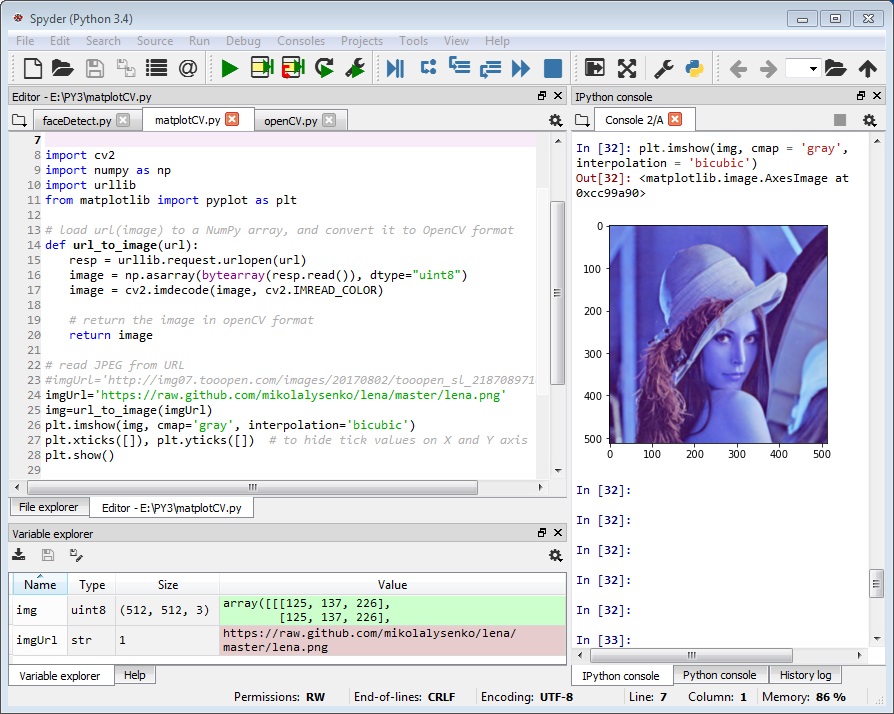
OpenCV可以讀取URL指定的動態影片檔, 但是靜態圖片檔不行. 下面這段程式碼則示範如何透過urllib套件讀取URL的靜態圖檔, 並透過matplotlib套件畫圖.
import cv2
import numpy as np
import urllib
from matplotlib import pyplot as plt
# load url(image) to a NumPy
array, and convert it to OpenCV format
def url_to_image(url):
resp
= urllib.request.urlopen(url)
image
= np.asarray(bytearray(resp.read()), dtype="uint8")
image
= cv2.imdecode(image, cv2.IMREAD_COLOR)
return
image
# read JPEG from URL
imgUrl=’https://nkmk.github.io/blog/img/scipy/lena_imsave.jpg’
img=url_to_image(imgUrl)
plt.imshow(img)
plt.xticks([]), plt.yticks([]) # to hide tick
values on X and Y axis
plt.show()
|
下圖是以Ipython
Console搭配Spyder編輯器的輸出結果, 如何? 好像回到了過去研究所的時光, 可以直接作影像處理了!
(意味著貴深深的MATLAB可以丟掉了!)
看圖描述事實與推測
我們再稍微改一下程式以判斷圖片中總共有多少人? 是個人照或是團體照? 若是團體照大概排了幾列, 當中是否有小孩等? 讓程式概略描述其對於所見圖片的內容.
import cv2
from PIL import Image
cv2.namedWindow("FaceDetectWin",cv2.WINDOW_AUTOSIZE)
jpg=’guc_members1.jpg'
img=cv2.imread(jpg)
classifierXml="{安裝路徑}\
\\Anaconda3\\pkgs\\opencv3-
faceCascade=cv2.CascadeClassifier(classifierXml)
faces=faceCascade.detectMultiScale(
img,
scaleFactor=1.1,
minNeighbors=4,
minSize=(10,10),
flags=cv2.CASCADE_SCALE_IMAGE)
i=1
aSum=0
yLoc={} # deect
face's position
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(128,255,0),2)
cv2.putText(img,str(i),(x+10,y+5),cv2.FONT_HERSHEY_SIMPLEX,0.7,(150,200,50),2)
cutFile="face"+str(i)+".jpg"
cutImage=Image.open(jpg).crop((x,y,x+w,y+h)).resize((200,200),Image.ANTIALIAS)
cutImage.save(cutFile)
k=format(y/90,"
aSum+=w*h
if yLoc.get(k)==None:
yLoc[k]=1
else:
yLoc[k]+=1
i+=1
nFace=len(faces)
nRow=len(yLoc)
avg=aSum/nFace
# possible kids
i=1
kids=[]
for (x,y,w,h) in faces:
if w*h < avg*0.55:
kids.append(str(i));
print("possible
kid:"+str(i)+":"+str(w*h))
i+=1
#看圖說故事
cv2.putText(img,"I can see "+str(nFace)+" people
in this picture",
(50,img.shape[0]-130),cv2.FONT_HERSHEY_SIMPLEX,1,(255,220,220),2)
if nFace>1:
cv2.putText(img,"It's a group photo",
(50,img.shape[0]-100),cv2.FONT_HERSHEY_SIMPLEX,1,(255,220,220),2)
cv2.putText(img,"People are arranged in "+str(nRow)+"
rows",
(50,img.shape[0]-70),cv2.FONT_HERSHEY_SIMPLEX,1,(255,220,220),2)
else:
cv2.putText(img,"It's a personal photo",
(50,img.shape[0]-100),cv2.FONT_HERSHEY_SIMPLEX,1,(255,220,220),2)
cv2.putText(img,"Faces "+str(kids)+" are possible
kids",
(50,img.shape[0]-40),cv2.FONT_HERSHEY_SIMPLEX,1,(255,220,220),2)
cv2.imshow("FaceDetectWin",img)
cv2.waitKey(0)
cv2.destroyAllWindows()
|


若以全體平均人臉高度的2倍高當作排列的位置, 而以全體平均人臉面積的55%面積大小當作小孩臉的分水嶺, 辨識與描述結果如下(都正確):
I can see 28 people in this picture
It’s a group photo
People are arranged in 5 rows
Faces [‘8’ , ‘23’ ] may be children
當然, 筆者舉的這個程式顯然太爛, 若遇到人物排列有景深的情況可能會誤判. 事實上, 厲害一點的程式已經能夠藉由辨識更多關鍵物件, 例如花朵、燭光、場景環境等, 來判斷圖像或動畫當時的可能情境並與客製化廣告做精準投射或提供創新的關聯性搜尋技術.
這不是AI啊!?
嗯. 若把AI比喻為登陸火星, 我們現在應該算跑到陽明山上丟上次摺的紙飛機吧!?
我們通常無法(也不須要處心積慮想)幹掉巨人, 但至少要學會站在巨人的肩膀上看遠一點, 順便看看前方有沒有新的機會是吧?